
How to build the Genesis Mission platform
President Trump signed an Executive Order, “Launching the Genesis Mission” on November 24, 2025, to supercharge scientific advancement in the United States by unlocking valuable data sets at our 17 National Labs, and exposing them to powerful AI models on a single platform, and letting supercomputers (huge GPU clusters, quantum computers) rip through them to make greater discoveries, faster.
It’s one of those ideas that seem obvious once stated. AI is getting better and better, but is limited by the data it works with. Our National Labs have a legacy of important research spanning decades. They all matured long before the cloud, which is designed to share data easily. So naturally, the data they create is scattered in various systems across geographies that don’t easily talk to each other. That’s why the order gives 120 days to create a plan “…for incorporating datasets from federally funded research, other agencies, academic institutions, and approved private-sector partners, as appropriate.” (Section 3.c.ii). Once all the data is central and accessible, untethered to its source, it’s a matter of spinning up powerful processing and getting to work; and that
If I want ChatGPT to draft a response to an email, I give it the email— easy. But If I want AI to find a more efficient nuclear fuel arrangement, I need to give it data on fuel arrangement. Where’s the data on fuel arrangement, and do I trust ChatGPT with it? This platform will solve that. How can you build this platform? Here’s a proposal.
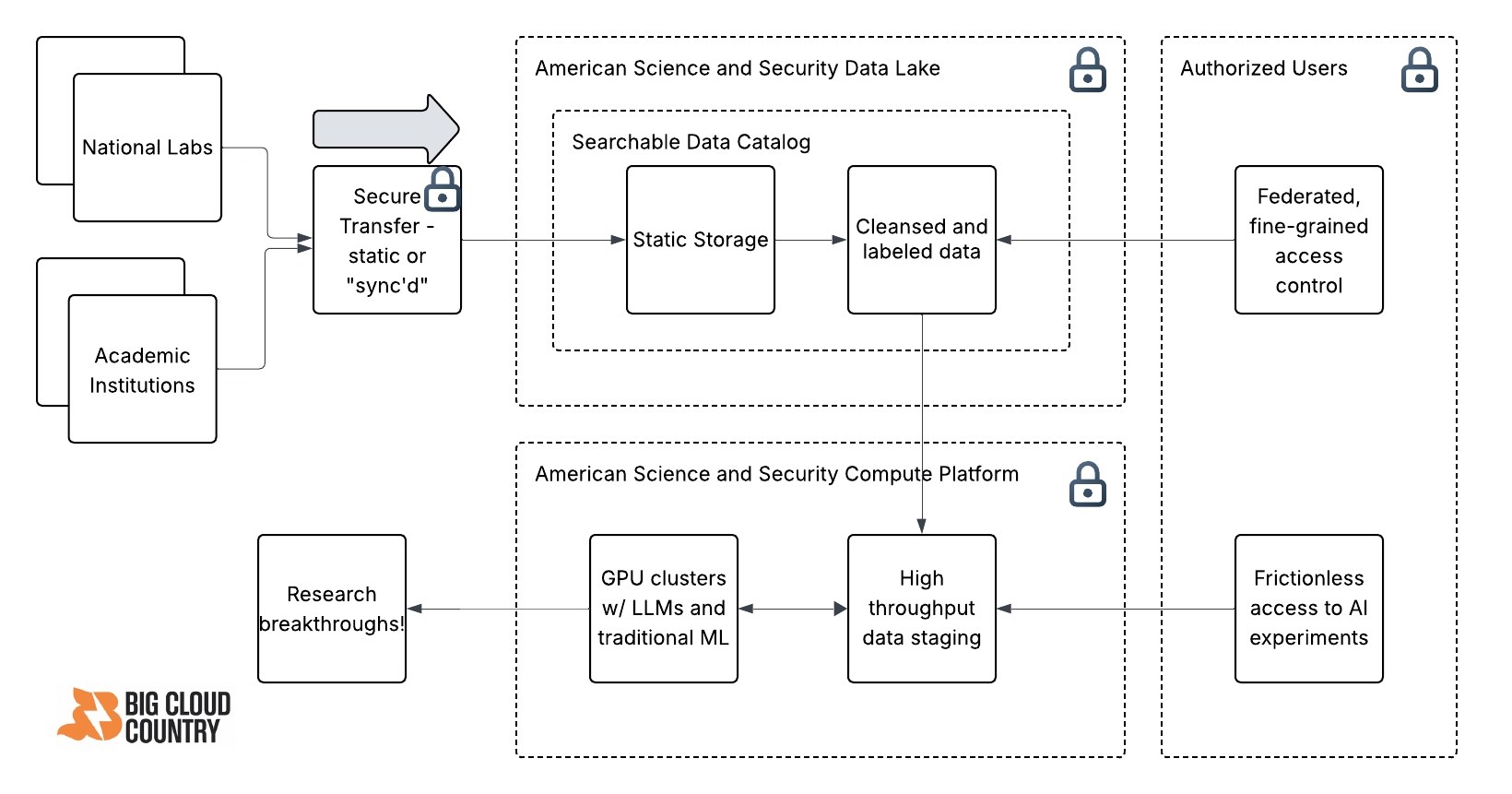
A standard cloud data lake with secure transfer from the National Labs, and clear separation of storage and compute, and fine-grained access control.
It starts with a big data lake…
One of the first use cases in the cloud was a data lake. It’s much cheaper to store gobs of data in the cloud. The vast majority of the data can be stored statically - as csv files, json files, parquet files. You don’t need a live database until later. Since storage is cheap, you don’t get so picky about what you keep - you just store it all. Then, data classifier systems crawl over the data to register the data that you have. This “metadata” is stored in a data catalog, which is your telephone book for all the data you keep in your data lake. The data catalog is the source of truth. It tells you everything about the data- where it’s from, what the columns are, what the data types are, how much there is, and crucially it should give you a 10 or 20-row sample so you can see if it’s what you want.
…with incentives to share data
In my experience this is basically where data lake projects fall apart almost immediately. Because the data being loaded is messy, broken, incomplete, or people just don’t care enough to load the data. That’s why the Genesis Mission needs to have incentives for the labs to share data. Tie the approval of research grants to the volume, quality, and value of data loaded. Loading a lot of high quality datasets that are clearly labeled? Your group at whatever lab you’re at is at the front of the queue for grants. Doing all that AND keeping it consistently synchronized with the data at your lab, so the platform data is current, within 24 hours? You are #1 in the queue, patriot.
Now that the data lake is populating with valuable, clean, labeled datasets, your data catalog starts to become trustworthy and the source of truth for the platform. People use the data catalog to find out what’s there, searching for example for neutron physics simulation data, and trusting that the results are real and valuable. You not only see the name and contents of the data, but you get a little sample in a table to see if it’s applicable to your project. This should take seconds.
… whose provenance and lineage is clear
Where does the data come from (provenance) and how has it been modified since it was created (lineage)? These are important features of a dataset that establish trust with a user. It’s common for datasets to be duplicated with just one more column added, or modified by changing the scale of calculations, or even something as simple as replacing a human-readable label with a random identifier. But are you looking at the authoritative original dataset, or a modified version? You want to know. You need to see and trust the provenance and lineage before using it.
…and is protected by fine-grained access control.
The Executive Order mentions a few different “buckets” of users based on security clearance, mission, and so on. If you squint you start to see how this translates into fine-grained access control. What that means is, your role as a user tells you what datasets and even what columns you can see. It governs whether you can create or delete or modify datasets. It governs how much data you can consume. In short, it is your key to the data lake, and if designed properly, you have “least privilege” access to all the data you can access, and nothing more. This is crucial to implement well, so that a university student, for example, is prevented from accessing cybersecurity research data, and in fact is prevented from ever knowing it exists in the first place. But the cybersecurity researcher should have access to it, while not having access to nuclear simulation data.
This takes some brains and elbow grease to setup and govern. But this problem has been solved very well in both Azure GovCloud and AWS GovCloud.
Separate Storage and Compute
Now you have picked the datasets you want. You are not going to run your AI work directly over the datalake. That will interfere with other people trying to look at the same data, plus the static storage systems are not setup for high throughput, which will be a great annoyance if you have a multi-gigabyte or larger dataset. So you take a copy of it and move it into an AI workspace. Again, AWS and Azure have both provided for this with AI Foundry and SageMaker respectively. The idea here is the separation of storage and compute. Data is stored by one machine, and completely different system runs your AI work, or your compute.
Now the fun part - GPU clusters
The Genesis Mission will no doubt marshal some serious compute resources to make this platform hum. Where will the compute clusters be? You can use those provided by AWS or Azure, and you can also federate the data securely to third-party clusters that specialize in making gobs of compute available. After all, there is never a guarantee that enough GPU clusters will be available. That, along with energy, is a top bottleneck in AI advancement in commercial players (hence the push for nuclear-powered AI datacenters). But I suspect the US will make some creative deals to make compute available from trusted enterprises, no doubt tapping X.ai, OpenAI, NVIDIA, or quantum providers and others to provision ultra-secure clusters that can receive context data over a secure network, run the job, and then output the results back to the AI workspace.
But not all research projects will need enormous compute. The majority of day-to-day research work benefits from the intermittent use of a small cluster or even a single GPU, and for that the cloud is well-equipped.
I have mentioned AWS and Azure as key cloud providers here, not only because of the excellence of their cloud systems, but also because of the excellence and “across the aisle” teamwork among internal teams at each company. Not all cloud providers can claim that their specialized teams (storage, compute, security) play well together. But Azure and AWS can.
A high level overview
The Genesis Mission is an ambitious project that seems obvious - open up the incredibly valuable work the National Labs have created over decades to other Labs, research institutions, and strategic commercial partners, to allow AI to do its thing on data that is bound to contain rich insights we haven’t unlocked before. But how to build the platform? I believe it’s hiding in plain sight: a classic cloud datalake with state-of-the-art access controls and smart decisions around how to get the data available and exposed to the most powerful AI models in the world.